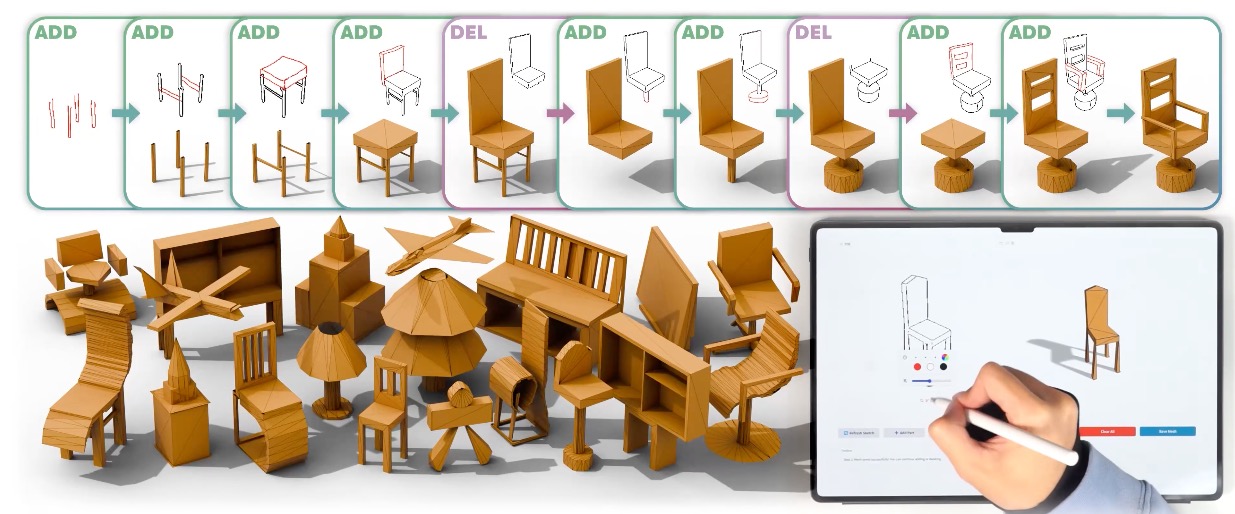
01 – MeshPad: Interactive Sketch-Conditioned Artist-Designed Mesh Generation and Editing
MeshPad enables interactive mesh creation and editing with sketches. We decompose this complex task into two sketch-conditioned operations: addition and deletion. Top: our method allows for a user to create and modify artist-designed triangle meshes by simply drawing and editing 2D sketches, achieving intuitive and interactive 3D modeling. Bottom (left): our method generates a variety of complex yet compact meshes. Bottom (right): our interactive user interface allows users to iteratively edit the mesh, with each edit step taking a few seconds (video speed up by 3x).
link: https://derkleineli.github.io/meshpad/
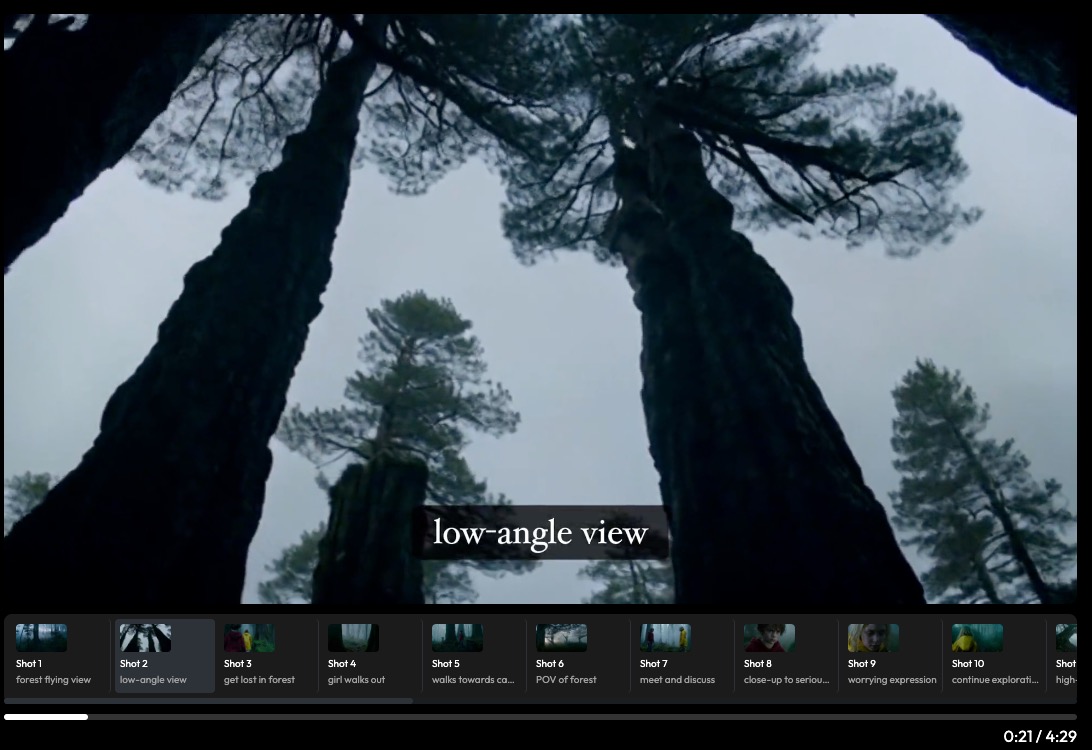
02 – Long Context Tuning for Video Generation
We propose Long Context Tuning (LCT) for scene-level video generation to bridge the gap between current single-shot generation capabilities and real-world narrative video productions such as movies. In this framework, a scene comprises a series of single-shot videos capturing coherent events that unfold over time with semantic and temporal consistency.
link: https://guoyww.github.io/projects/long-context-video/
03 – MIDI: Multi-Instance Diffusion for Single Image to 3D Scene Generation
Given an input image of a scene, we segment it into multiple parts and use a multi-instance diffusion model conditioned on those images to generate compositional 3D instances of the scene. These 3D instances can be directly composed into a scene. The total processing time runs in as little as 40 seconds.
link: https://huanngzh.github.io/MIDI-Page/

04 – Redirecting Camera Trajectory for Monocular Videos via Diffusion Models
TrajectoryCrafter can generate high-fidelity novel views from casually captured monocular video, while also supporting highly precise pose control.
link: https://github.com/TrajectoryCrafter/TrajectoryCrafter
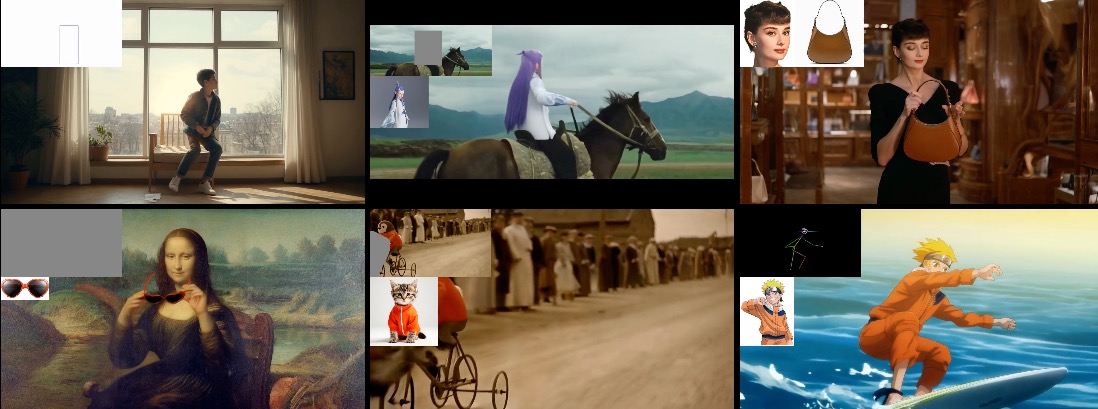
05 – VACE All-in-One Video Creation and Editing
VACE creatively provides solutions for video generation and editing within a single model, allowing users to explore diverse possibilities and streamline their workflows effectively, offering capabilities including Move-Anything, Swap-Anything, Reference-Anything, Expand-Anything, Animate-Anything and more.
is an all-in-one model designed for video creation and editing. It encompasses various tasks, including reference-to-video generation (R2V), video-to-video editing (V2V), and masked video-to-video editing (MV2V), allowing users to compose these tasks freely. This functionality enables users to explore diverse possibilities and streamline their workflows effectively, offers a range of capabilities, such as Move-Anything, Swap-Anything, Reference-Anything, Expand-Anything, Animate-Anything, and more.
link: https://ali-vilab.github.io/VACE-Page/
gitHub: https://github.com/ali-vilab/VACE

06 – SANA-Sprint: One-Step Diffusion with Continuous-Time Consistency Distillation
We introduce Sana, a text-to-image framework that can efficiently generate images up to 4096 × 4096 resolution. Sana can synthesize high-resolution, high-quality images with strong text-image alignment at a remarkably fast speed, deployable on laptop GPU
link: https://nvlabs.github.io/Sana/Sprint/
07 – Pika collection on Wan OpenSource
link: https://huggingface.co/collections/Remade-AI/wan21-14b-480p-i2v-loras-67d0e26f08092436b585919b
Example squish
prompt: In the video, a miniature dog is presented. The dog is held in a person’s hands. The person then presses on the dog, causing a sq41sh squish effect. The person keeps pressing down on the dog, further showing the sq41sh squish effect.
Download link:
squish_18.safetensors – LoRA Model File
wan_img2video_lora_workflow.json – Wan I2V with LoRA Workflow for ComfyUI